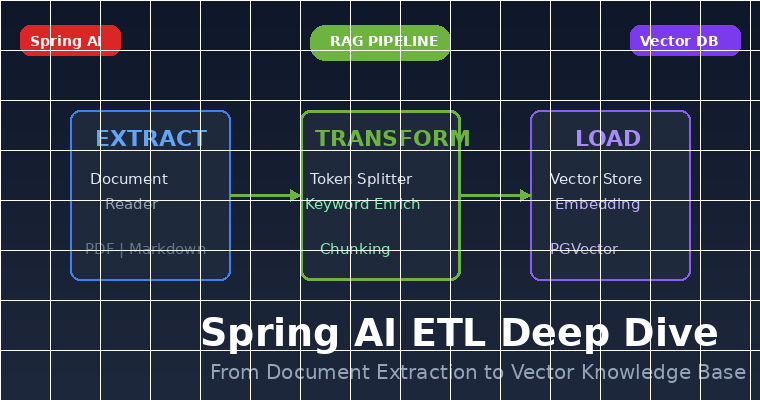
一、前言:为什么需要ETL?
在学习Spring AI的过程中,我发现很多教程只关注如何调用大模型API,却忽略了企业级AI应用的核心痛点:如何让AI读懂你的私有文档?
无论是构建客服机器人、知识库问答,还是在做AI咨询项目,都需要解决一个基础问题:如何将杂乱无章的文档(PDF、Markdown、网页)转化为AI可理解的向量知识库?
这就是ETL(Extract-Transform-Load)的价值所在。本文基于Spring AI官方文档和实战项目,深度拆解ETL Pipeline的完整工作流程。
学习路径建议:本文是RAG系列的第一篇,重点讲解数据预处理。后续将更新向量检索和Prompt工程实战。
二、RAG工作流程:先理解全局,再深入细节
在讲解ETL之前,必须理解RAG(Retrieval Augmented Generation,检索增强生成)的完整工作流程。根据Spring AI官方文档,RAG的本质是:
通过"向量相似度检索+上下文增强",让大模型基于权威文档生成答案,而非凭空"幻觉"(Hallucination)。
2.1 两阶段架构解析
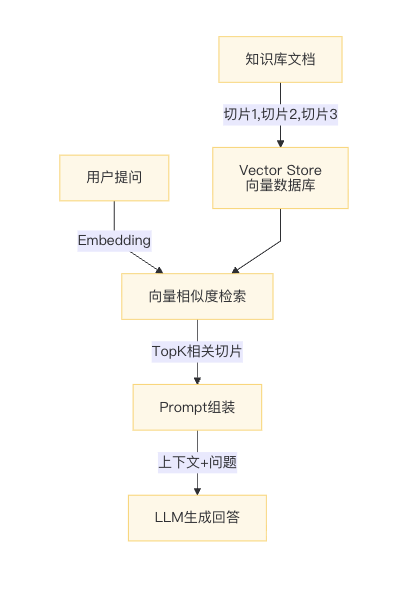
阶段一:离线索引(Indexing)
-
Document Loading:读取PDF、Markdown、HTML等原始文档
-
Splitting & Chunking:将长文档切分为适合模型上下文的片段(Chunks)
-
Embedding & Storing:通过Embedding模型转换为向量,存入向量数据库
阶段二:在线检索(Retrieval & Generation)
-
Query Embedding:将用户问题转为向量
-
Similarity Search:在向量库中检索TopK个最相似文档片段
-
Context Injection:将检索结果作为上下文注入Prompt,调用LLM生成答案
而我们本文要深度讲解的,正是RAG四大流程中最基础也最容易被忽视的——第一环节:文档的ETL处理。
三、ETL核心概念:Spring AI的三板斧
根据Spring AI ETL文档,ETL Pipeline包含三大核心组件:
| 组件 | 职责 | 类比 |
|---|---|---|
| DocumentReader | 从各种数据源(本地、网络、数据库)读取原始内容 | Extractor(抽取) |
| DocumentTransformer | 清洗、分割、元数据增强,加工为适合向量化的格式 | Transform(转换) |
| DocumentWriter | 将处理后的文档写入向量数据库或文件系统 | Load(加载) |
3.1 Document的本质:不只是文本
在Spring AI中,
Document对象比我们日常理解的"文档"更广泛:public class Document {
private String id; // 唯一标识
private String content; // 核心文本内容
private Map<String, Object> metadata; // 元数据(来源、作者、时间等)
private MediaType mediaType; // 可选:图片、音频、视频
}关键认知:Spring AI的Document是多模态的,支持文本+媒体附件,这为后续处理复杂场景(如图文混合RAG)预留了扩展性。
四、DocumentReader:数据抽取的十八般武艺
4.1 核心职责
从异构数据源(PDF、网页、数据库、飞书文档)读取内容,统一封装为
Document对象列表。4.2 实现类全景图与选型指南
Spring AI内置了丰富的Reader实现,以下是生产环境常用选型:
| 实现类 | 适用场景 | 核心特点 | 依赖引入 |
|---|---|---|---|
TextReader |
纯文本(.txt) | 简单高效,支持自定义元数据 | spring-ai-core |
PagePdfDocumentReader |
PDF文档 | 按页读取,保留页码元数据 | spring-ai-pdf-document-reader |
MarkdownDocumentReader |
Markdown | 解析标题层级,保留大纲结构 | spring-ai-markdown-document-reader |
TikaDocumentReader |
多格式(Word/PPT/Excel) | 基于Apache Tika,自动识别格式 | spring-ai-tika |
JsoupDocumentReader |
HTML网页 | 使用JSoup爬取,支持CSS选择器过滤 | spring-ai-jsoup |
JsonReader |
JSON数据 | 提取指定字段作为内容 | spring-ai-core |
社区扩展(Spring AI Alibaba): 还包括飞书文档读取器、B站视频字幕提取器、GitHub文档加载器、邮件读取器等。
4.3 实战:项目的文档抽取
在项目中,知识库是Markdown格式的情感咨询文档,使用
MarkdownDocumentReader进行抽取:@Component
public class LoveDocumentLoader {
@Autowired
private MarkdownDocumentReader markdownReader;
public List<Document> loadKnowledgeBase() {
// 读取resources/love-tips/目录下的所有.md文件
List<Document> documents = markdownReader.read(
new FileSystemResource("knowledge-base/")
);
System.out.println("成功加载 " + documents.size() + " 个文档片段");
// DEBUG输出:此时会将每个.md文件作为一个Document对象
// 如果文件内有---分隔符,会被切分为多个Document
return documents;
}
}DEBUG验证: 运行单元测试后可以看到,3个原始Markdown文件被提取为15个
Document对象(因为文件内有水平分割线---进行了初步切分)。五、DocumentTransformer:数据质量的决定性环节
如果说Reader是"进货",Transformer就是"精加工"。这是RAG效果的核心瓶颈所在。
Spring AI的
DocumentTransformer继承自Function<List<Document>, List<Document>>,即:输入一批文档,输出加工后的一批文档。5.1 为什么需要二次拆分?(重要概念)
很多初学者疑惑:Reader已经拆分过一次了(15个文档),为什么还要用Transformer再拆分?
关键区别:
表格
| 维度 | Reader的拆分(粗分) | Transformer的拆分(细分) |
|---|---|---|
| 目的 | 文件级隔离 | 适配模型上下文长度,保留语义边界 |
| 粒度 | 大段落(可能几千token) | 小块(通常200-800 token) |
| 依据 | 文件格式特征(---、分页符) | 语义边界(段落、句子)+ Token限制 |
| 元数据 | 基础信息(文件名、路径) | 可添加AI生成的摘要、关键词 |
类比理解:
-
Reader把一本书分成"章节"(15章)
-
Transformer把章节切成适合阅读的"段落"(可能每章再分2-3段,共30-40段)
5.2 文本分割器(Text Splitters)
核心实现类:
TokenTextSplitter这是最常用的分割器,基于Token数量(而非字符数)进行智能切分,保留语义边界(句子/段落完整性)。
@Component
public class LoveDocumentSplitter {
public List<Document> splitDocuments(List<Document> documents) {
// 参数详解:
// 1. defaultChunkSize: 目标块大小(token数),默认800
// 2. minChunkSizeChars: 最小字符数,低于此值会合并到相邻块(默认350)
// 3. minChunkLengthToEmbed: 最小嵌入长度,过滤噪音(默认5)
// 4. maxNumChunks: 最大块数,防止超大文档爆炸(默认10000)
// 5. keepSeparator: 是否保留换行符等分隔符(默认true)
TokenTextSplitter splitter = new TokenTextSplitter(
200, // 目标200 tokens/块(适合短问答场景)
100, // 最小100字符
10, // 至少10 tokens
5000, // 最多5000块
true // 保留分隔符,保持格式
);
return splitter.apply(documents);
}
}效果验证: 之前Reader输出的15个文档,经过
TokenTextSplitter处理后,被细分为30个粒度更小的Chunks,更适合向量化检索。5.3 元数据增强器(Metadata Enrichers)
单纯的文本切片往往缺乏上下文,通过AI自动生成元数据可以显著提升检索精准度。
① KeywordMetadataEnricher:关键词提取
@Component
public class KeywordEnricher {
@Autowired
private ChatModel chatModel; // 使用DeepSeek/Qwen等
public List<Document> enrichWithKeywords(List<Document> documents) {
// 为每个文档提取5个关键词,存入metadata
KeywordMetadataEnricher enricher =
new KeywordMetadataEnricher(chatModel, 5);
return enricher.apply(documents);
}
}效果对比:
-
增强前:metadata只有
{source: "file.md", page: 1} -
增强后:metadata额外包含
{keywords: ["恋爱技巧", "沟通", "亲密关系"]}
② SummaryMetadataEnricher:上下文摘要 不仅为当前文档生成摘要,还能关联前后相邻文档的摘要,解决切片后的"断章取义"问题。
5.4 ContentFormatter:提示词工程的前置处理
在将Document送入LLM前,需要控制元数据的展示格式。
DefaultContentFormatter提供了精细的控制:DefaultContentFormatter formatter = DefaultContentFormatter.builder()
// 元数据展示模板:key: value
.withMetadataTemplate("{key}: {value}")
// 多行元数据分隔符
.withMetadataSeparator("\n")
// 最终组合模板:元数据 + 换行 + 内容
.withTextTemplate("{metadata_string}\n\n{content}")
// 推理时排除的字段(避免向量数据污染Prompt)
.withExcludedInferenceMetadataKeys("embedding", "vector_id")
// 嵌入时排除的字段(避免URL等噪音干扰相似度计算)
.withExcludedEmbedMetadataKeys("source_url", "timestamp")
.build();
// 使用方式
String promptContent = formatter.format(document, MetadataMode.INFERENCE);为什么这很重要?
-
如果不格式化,直接塞给LLM可能是乱码:
{"embedding": [0.1,0.3,...], "vector_id": "123"}\n\n内容... -
格式化后LLM看到的是结构清晰的:
source: 恋爱指南.md page: 12 keywords: 沟通技巧,婚后关系 Spring AI 是...(正文)
六、DocumentWriter:数据归宿的多种选择
6.1 核心实现类
| 实现类 | 目标存储 | 适用场景 |
|---|---|---|
VectorStore子类 |
向量数据库(PGVector/Milvus/Chroma) | 主要场景:语义检索 |
FileDocumentWriter |
本地文件 | 备份、日志记录 |
向量数据库写入示例:
@Component
public class KnowledgeBaseWriter {
@Autowired
private VectorStore vectorStore; // 自动注入配置的PGVector/Milvus等
public void storeDocuments(List<Document> documents) {
// 自动完成:1) Embedding向量化 2) 存储到数据库
vectorStore.accept(documents);
System.out.println("知识库已持久化,共 " + documents.size() + " 条记录");
}
}6.2 多路由写入策略
生产环境常需要同时写入多个存储(比如主库存PGVector,缓存存Redis,备份存文件),可以通过组合Writer实现:
@Component
public class MultiRouteWriter {
public void writeToMultipleStores(List<Document> docs) {
// 主存储:向量数据库(用于检索)
vectorStore.accept(docs);
// 备份存储:文件(用于审计)
new FileDocumentWriter("backup.txt", true, MetadataMode.ALL)
.accept(docs);
}
}七、完整Pipeline串联:实战代码
将上述组件组合为完整的ETL Pipeline:
@Service
public class LoveKnowledgeBaseETL {
@Autowired private MarkdownDocumentReader reader;
@Autowired private TokenTextSplitter splitter;
@Autowired private KeywordMetadataEnricher enricher;
@Autowired private VectorStore vectorStore;
@PostConstruct // 应用启动时自动执行
public void buildKnowledgeBase() {
// 1. Extract:读取恋爱咨询文档
List<Document> rawDocs = reader.read(
new FileSystemResource("knowledge-base/")
);
System.out.println("Step 1 - 读取完成: " + rawDocs.size() + " 个原始文档");
// 2. Transform:切分 + 增强
List<Document> chunks = splitter.apply(rawDocs);
System.out.println("Step 2 - 切分完成: " + chunks.size() + " 个片段");
List<Document> enrichedChunks = enricher.apply(chunks);
System.out.println("Step 3 - 增强完成: 已添加关键词元数据");
// 3. Load:存入向量库
vectorStore.accept(enrichedChunks);
System.out.println("Step 4 - 加载完成: 知识库构建完毕!");
}
}执行结果:
Step 1 - 读取完成: 15 个原始文档
Step 2 - 切分完成: 30 个片段
Step 3 - 增强完成: 已添加关键词元数据
Step 4 - 加载完成: 知识库构建完毕!八、总结与进阶路线
8.1 核心要点回顾
-
DocumentReader:解决"从哪读"的问题,支持Markdown/PDF/HTML等多格式
-
DocumentTransformer:解决"怎么处理"的问题,Token切分策略和元数据增强是RAG效果的决胜手
-
DocumentWriter:解决"存到哪"的问题,通常是向量数据库
8.2 性能优化建议
-
切分粒度:不是越小越好,过小的Chunks会丢失上下文。建议问答场景200-400 tokens,长文档摘要场景800-1000 tokens。
-
重叠策略:相邻Chunks保留10%-20%的重叠内容,避免"断章取义"。
-
批量处理:大规模文档处理时,使用
List<Document>批量操作,减少数据库往返。
8.3 下一步学习
-
向量数据库选型对比(PGVector vs Milvus vs Chroma)
-
RAG的检索策略:相似度阈值调优、混合检索(向量+关键词)
-
Spring AI的ChatClient与Prompt Templating实战